Why Islo snapshots are the missing primitive
Three things meta-harness needs from its runtime:
- Reproducible eval environments — every candidate harness
runs against the same setup, otherwise the score is noise.
- Massive parallelism — testing $N$ candidates $\times K$
tasks adds up fast.
- Persistent traces — the proposer needs to read
stdout/stderr/agent-thoughts from runs that completed an hour ago.
Islo’s primitives map 1:1:
islo snapshot save meta-base
islo use mh-cand-7 --snapshot meta-base ...
islo logs mh-cand-7 --type agent
Add islo gateway (deny-by-default egress to prevent reward-hacking) and
--source github://owner/repo (clone the workload at boot), and the wiring
is basically free. Harbor — Islo
Labs’ framework for agent evaluations and RL environments — slots in as the
workload spec.
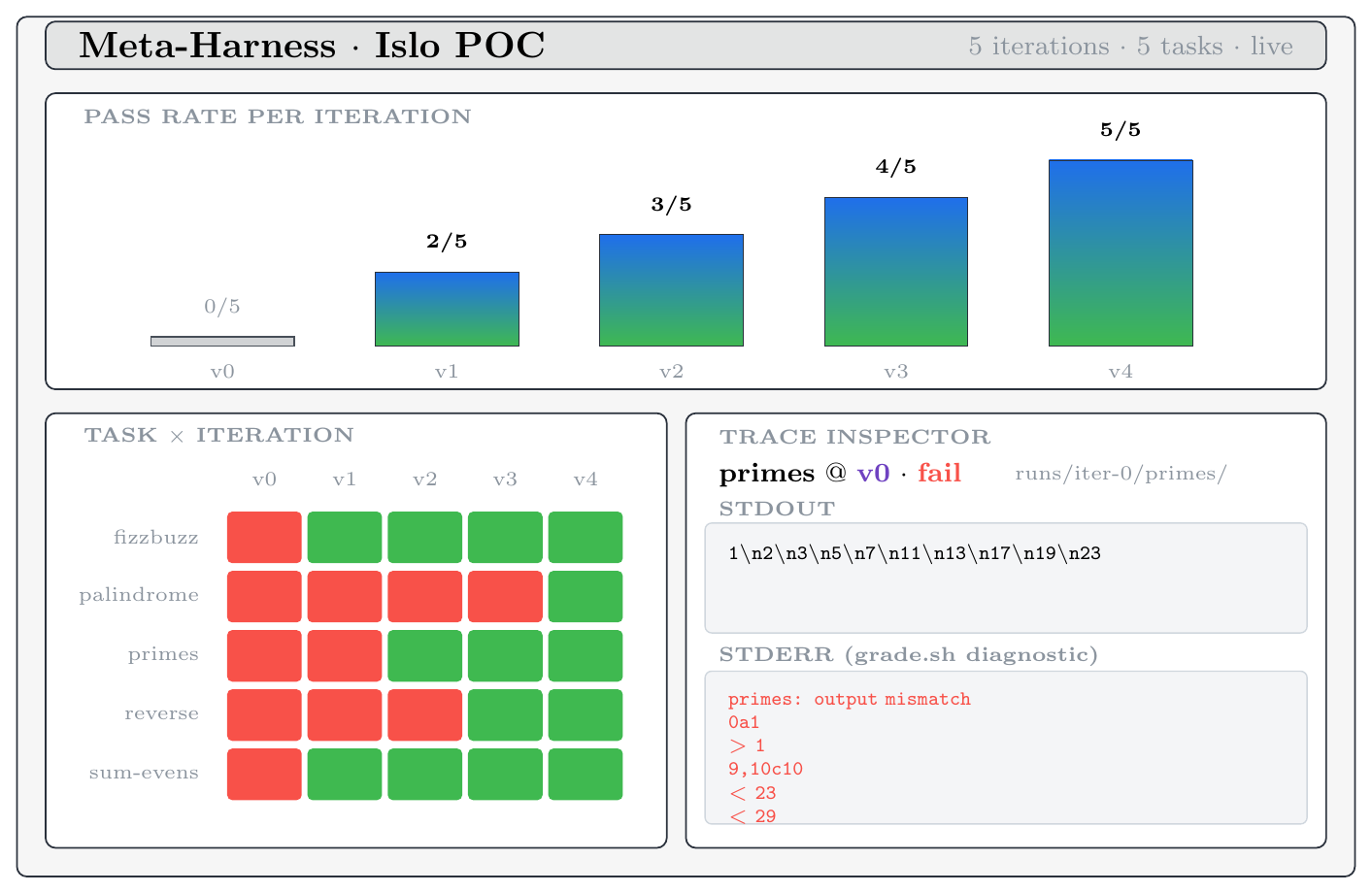
The POC
tasks/
harness/v0/
bin/
meta-harness
agent-sim.py
proposer.py
viz/index.html
runs/
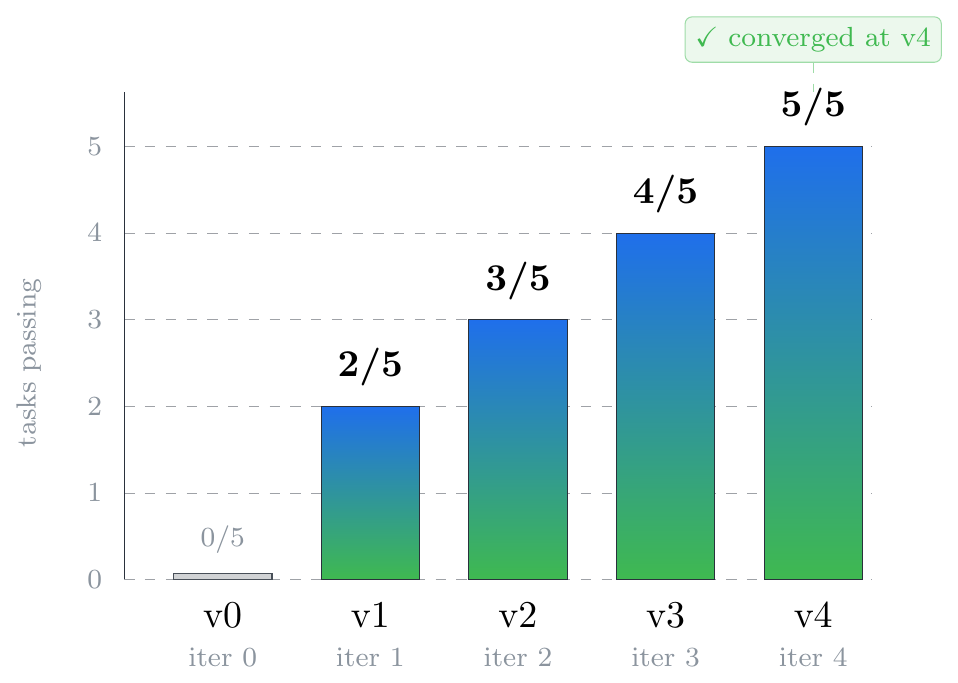
The agent is a Python simulator that’s intentionally buggy — until the
system prompt contains the right hint keyword. The loop is therefore deterministic
and offline, runs in seconds, but the wiring is identical to what you’d ship
against real Claude on Islo. The proposer is 80 lines: read
runs/iter-N/, find which tasks failed, look up the missing hint for that
task, append it to a new harness/v{N+1}/system.md. A real proposer would
be:
islo use --snapshot meta-base --agent claude --task "
Examine /workspace/runs/iter-${N}. Find a common failure mode in the
grade.sh stderr. Write /workspace/harness/v${N+1}/system.md as a small
edit on top of v${N}/system.md to fix it."
Same input, same output contract. The orchestrator already has the stub.